

GPT-4 أجرى امتحان العلاج الطبيعي! النتيجة صدمت

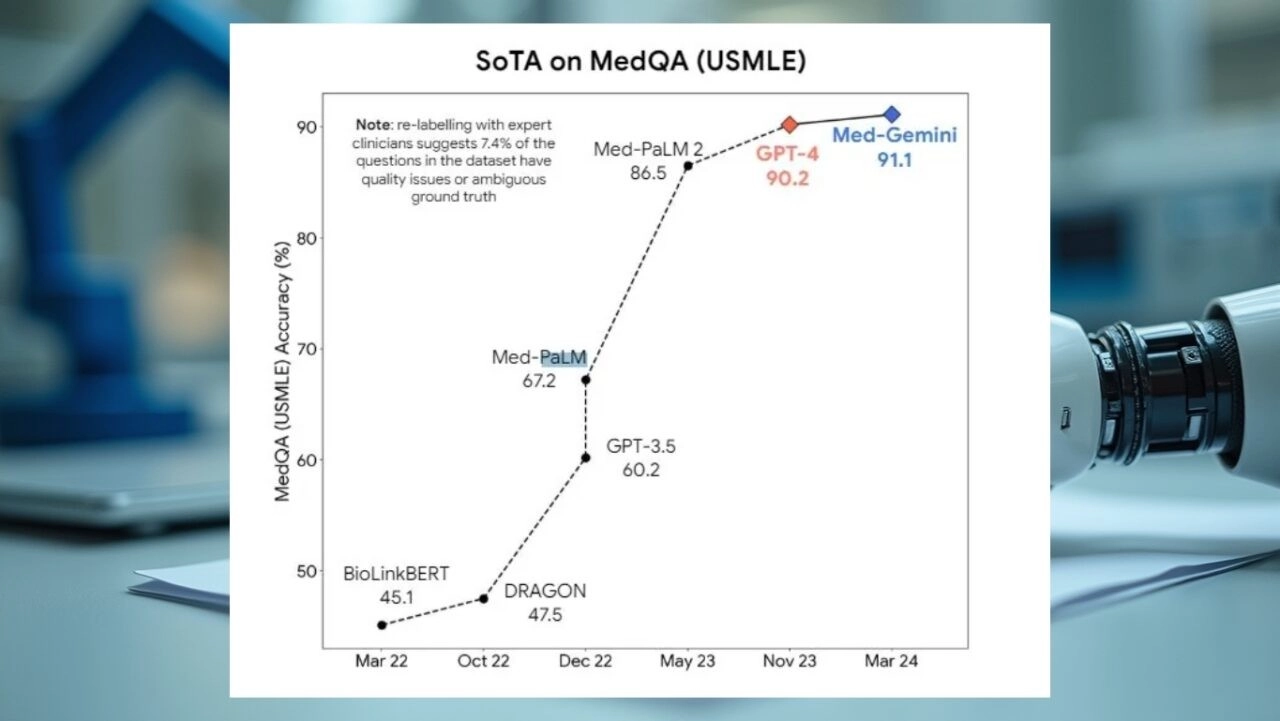
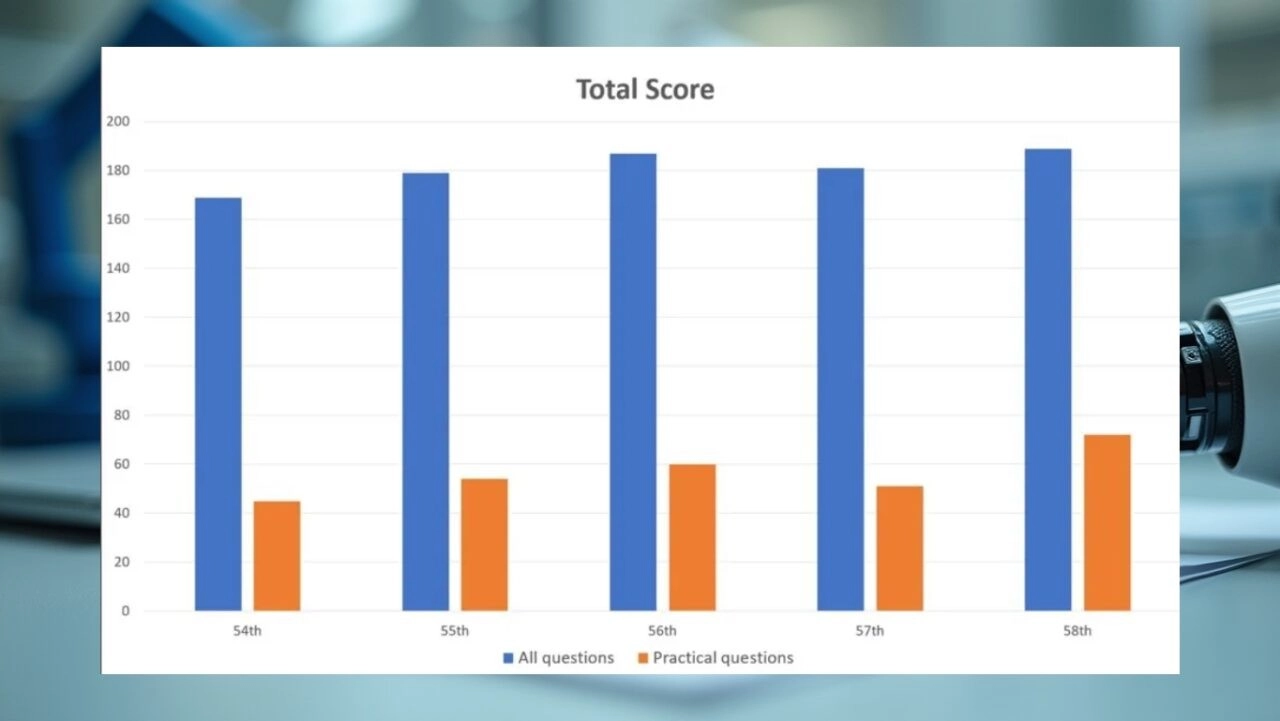

فاجأ نجاح نموذج الذكاء الاصطناعي GPT-4 في اختبار العلاج الطبيعي في اليابان المتخصصين في المجال الطبي. وحققت نسبة دقة عالية.
نجح نموذج لغة الذكاء الاصطناعي القوي GPT-4 من OpenAI في اجتياز الاختبار الوطني المتخصص في العلاج الطبيعي في اليابان دون أي تدريب إضافي أو إعداد خاص. أثبت النجاح الباهر في عالم الطب مرة أخرى قدرات GPT-4 وإمكاناته في مختلف مجالات المعرفة. كشفت نتائج البحث أن GPT-4 فعال جدًا في الأسئلة النصية، ولكن لديه بعض القيود في الأسئلة ذات المحتوى التقني والمرئي. إليكم التفاصيل…
كان أداء النموذج قويًا جدًا في الأسئلة النصية، حيث حقق معدل دقة قدره 80.1%. ومع ذلك، انخفض معدل دقة النموذج إلى 46.6% في الأسئلة التي تحتوي على تفاصيل فنية ومدعومة بالمرئيات. كانت الأسئلة التي تتضمن جداول وصور على وجه الخصوص هي المجالات التي واجه فيها النموذج أكبر قدر من الصعوبة؛ وظل معدل الدقة لمثل هذه الأسئلة عند مستوى منخفض قدره 35.4%.
تُظهر هذه النتائج أنه على الرغم من قدرات GPT-4 الفائقة في معالجة اللغة، إلا أنه يعاني من قيود في المشكلات المعقدة الممزوجة بالبيانات المرئية. ومن النتائج الأخرى المثيرة للاهتمام في البحث أن GPT-4 حقق أيضًا نتائج ناجحة جدًا في الأسئلة اليابانية، على الرغم من أنه تم تدريبه إلى حد كبير على مجموعات البيانات الإنجليزية.
ويكشف هذا أيضًا عن قدرات النموذج المتعددة اللغات وقدرته على الأداء بفعالية بلغات مختلفة. وبشكل عام، يعد معدل نجاح GPT-4 بالتأكيد خطوة مهمة في استكشاف إمكانات وحدود الذكاء الاصطناعي في مجالات المعلومات المعقدة.
على الرغم من كونه قويًا فيما يتعلق بالمشكلات النصية، فمن الواضح أنه يحتاج إلى مزيد من التحسين في المشكلات المرئية والتقنية. ومع ذلك، أظهر هذا النجاح للعالم مرة أخرى الدور الذي يمكن أن تلعبه تقنيات الذكاء الاصطناعي في مجالات مثل التعليم والامتحانات المهنية.
نجح نموذج لغة الذكاء الاصطناعي القوي GPT-4 من OpenAI في اجتياز الاختبار الوطني المتخصص في العلاج الطبيعي في اليابان دون أي تدريب إضافي أو إعداد خاص. أثبت النجاح الباهر في عالم الطب مرة أخرى قدرات GPT-4 وإمكاناته في مختلف مجالات المعرفة. كشفت نتائج البحث أن GPT-4 فعال جدًا في الأسئلة النصية، ولكن لديه بعض القيود في الأسئلة ذات المحتوى التقني والمرئي. إليكم التفاصيل…
دخل GPT-4 إلى امتحان أخصائي العلاج الطبيعي الوطني في اليابان: حقق معدل نجاح قدره 73.4%
يتكون الاختبار الوطني المتخصص في العلاج الطبيعي في اليابان من إجمالي 200 سؤال، بما في ذلك 160 سؤالًا للمعرفة العامة و40 سؤالًا تدريبيًا. يختبر هذا الاختبار مهارات المشاركين في الذاكرة والفهم والتطبيق والتحليل والتقييم. قام الباحثون بتحميل 1000 سؤال من هذا الاختبار إلى GPT-4 وقارنوا إجابات النموذج بالإجابات الرسمية. وأظهرت النتائج أن GPT-4 أجاب على 73.4% من هذه الأسئلة بشكل صحيح.كان أداء النموذج قويًا جدًا في الأسئلة النصية، حيث حقق معدل دقة قدره 80.1%. ومع ذلك، انخفض معدل دقة النموذج إلى 46.6% في الأسئلة التي تحتوي على تفاصيل فنية ومدعومة بالمرئيات. كانت الأسئلة التي تتضمن جداول وصور على وجه الخصوص هي المجالات التي واجه فيها النموذج أكبر قدر من الصعوبة؛ وظل معدل الدقة لمثل هذه الأسئلة عند مستوى منخفض قدره 35.4%.
تُظهر هذه النتائج أنه على الرغم من قدرات GPT-4 الفائقة في معالجة اللغة، إلا أنه يعاني من قيود في المشكلات المعقدة الممزوجة بالبيانات المرئية. ومن النتائج الأخرى المثيرة للاهتمام في البحث أن GPT-4 حقق أيضًا نتائج ناجحة جدًا في الأسئلة اليابانية، على الرغم من أنه تم تدريبه إلى حد كبير على مجموعات البيانات الإنجليزية.
ويكشف هذا أيضًا عن قدرات النموذج المتعددة اللغات وقدرته على الأداء بفعالية بلغات مختلفة. وبشكل عام، يعد معدل نجاح GPT-4 بالتأكيد خطوة مهمة في استكشاف إمكانات وحدود الذكاء الاصطناعي في مجالات المعلومات المعقدة.
على الرغم من كونه قويًا فيما يتعلق بالمشكلات النصية، فمن الواضح أنه يحتاج إلى مزيد من التحسين في المشكلات المرئية والتقنية. ومع ذلك، أظهر هذا النجاح للعالم مرة أخرى الدور الذي يمكن أن تلعبه تقنيات الذكاء الاصطناعي في مجالات مثل التعليم والامتحانات المهنية.
أخبار ذات صلة







